

DataPelago today emerged from stealth with a new virtualization layer that it says will allow users to move AI, data analytics, and ETL workloads to whatever physical processor they want, without making code changes, thereby bringing potentially large new efficiency and performance gains to the fields of data science, data analytics, and data engineering, as well as HPC.

The advent of generative AI has triggered a scramble for high-performance processors that can handle the massive compute demands of large language models (LLMs). At the same time, companies are searching for ways to squeeze more efficiency out of their existing compute expenditures for advanced analytics and big data pipelines, all while dealing with the never-ending growth of structured, semi-structured, and unstructured data.
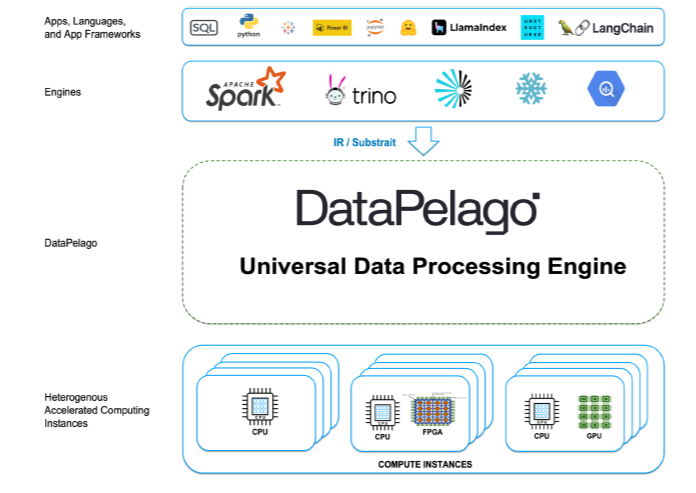
The folks at DataPelago have responded to these market signals by building what they call a universal data processing engine that eliminates the need to hard wire data-intensive workloads to underlying compute infrastructure, thereby freeing users to run big data, advanced analytics, AI, and HPC workloads to whatever public cloud or on-prem system they have available or that meets their price/performance requirements.
“Just like Sun built the Java Virtual Machine or VMware invented the hypervisor, we are building a virtualization layer that runs in the software, not in hardware,” says DataPelago Co-founder and CEO Rajan Goyal. “It runs on software, which gives a clean abstraction for anything upside.”
The DataPelago virtualization layer sits between the query engine, like Spark, Trino, Flink, and regular SQL, and the underlying infrastructure composed of storage and physical processors, such as CPUs, GPUs, TPUs, FPGAs, etc. Users and applications can submit jobs as they normally would, and the DataPelago layer will automatically route and run the job to the appropriate processor in order to meet the availability or cost/performance characteristics set by the user.
At a technical level, when a user or application executes a job, such as a data pipeline job or a query, the processing engine, such as Spark, converts it into a plan, and then DataPelago will call an open source layer, such as Apche Gluten, to convert that plan into an Intermediate Representation (IR) using open standards like Substrait or Velox. The plan is sent to the worker node in the DataOS component of the DataPelago platform, while the IR is converted into an executable Data Flow Graph (DFG) that runs in the DataOS component of the DataPelago platform. DataVM then evaluates the nodes of the DFG and dynamically maps them to the right processing element, according to the company.
Having an automated method to match the right workloads to the right processor will be a boon to DataPelago customers, who in many cases have not benefited from the performance capabilities they expected when adopting accelerated compute engines, Goyal says.
“CPUs, FPGAs and GPUs–they have their own sweet spot, like the SQL workload or Python workload has a variety of operators. Not all of them run efficiently on CPU or GPU or FPGA,” Goyal tells BigDATAwire. “We know those sweet spots. So our software at runtime maps the operators to the right … processing element. It can break this massive query or workload into thousands of tasks, and some will run on CPUs, some will run on GPUs, some will run FPGA. That’s innovative adaptive mapping at runtime to the right computing element is missing in other frameworks.”
DataPelago obviously can’t exceed the maximum performance capabilities that an application can get by natively developing natively in CUDA for Nvidia GPUs, ROCm for AMD GPUs, or LLVM for high-performance CPU jobs, Goyal says. But the company’s product can get much closer to maxing out whatever application performance is available from those programming layers, and doing so while shielding them from the underlying complexity and without tethering users and their applications to those middleware layers, he says.
“There is a huge gap in the peak performance that the GPUs are expected versus what applications get. We are bridging that gap,” he says. “You’ll be shocked that applications, even the Spark workloads running on the GPUs today, get less than 10% of the GPU’s peak FLOPS.”
One reason for the performance gap is the I/O bandwidth, Goyal says. GPUs have their own local memory, which means you have to move data from the host memory to the GPU memory to utilize it. People often don’t factor that data movement and I/O into their performance expectations when moving to GPUs, Goyal says, but DataPelago can eliminate the need to even worry about it.
“This virtual machine handles it in such a way [that] we fuse operators, we execute Data Flow Graphs,” Goyal says. “Things don’t move out of one domain to another domain. There is no data movement. We run in a streaming fashion. We don’t do store and forward. As a result, I/O are a lot more reduced, and we are able to peg the GPUs to 80 to 90% of their peak performance. That’s the beauty of this architecture.”
The company is targeting all sorts of data-intensive workloads that organizations are trying to speed up by running atop accelerated computing engines. That includes SQL queries for ad hoc analytics using SQL, Spark, Trino, and Presto, ETL workloads built using SQL or Python, and streaming data workloads using frameworks like Flink. Generative AI workloads can benefit, both at the LLMs training stage as well as at runtime, thanks to DataPelago’s capability to accelerate retrieval augmented generation (RAG), fine-tuning, and creation of vector embeddings for a vector database, Goyal says.
“So it’s a unified platform to do both the classic lakehouse analytics and ETL, as well as the GenAI pre-processing of the data,” he says.
Customers can run DataPelago on-prem or in the cloud. When running next to a cloud lakehouse, such as AWS EMR or DataProc from Google Cloud, the system has the capability to get the same amount of work previously done with a 100-node cluster with a 10-node cluster, Goyal says. While the queries themselves run 10x faster with DataPelago, the end result is a 2x improvement in total cost of ownership after licensing and maintenance are factored in, he says.
“But most importantly, it’s without any change in the code,” he says. “You are writing Airflow. You’re using Jupyter notebooks, you’re writing Python or PySpark, Spark or Trino–whatever you’re running on, they continue to remain unmodified.”
The company has benchmarked its software running against some of the fastest data lakehouse platforms around. When run against Databricks Photon, which Goyal calls “the gold standard,” DataPelago showed a 3x to 4x performance boost, he says.
Goyal says there’s no reason why customers couldn’t use the DataPelago virtualiation layer to accelerate scientific computing workloads running on HPC setups, including AI or simulating and modeling workloads, Goyal says.
“If you have a custom code written for a specific hardware, where you’re optimizing for an A100 GPU which has 80 gigabyte GPU memory, so many SMs, and so many threads, then you can optimize for that,” he says. “Now you are kind of orchestrating your low-level code and kernels so that you’re kind of maximizing your FLOPS or the operations per second. What we have done is providing an abstraction layer where now that thing is done underneath and we can hide it, so it gives extensibilyit and paplyin the same principle.
“At the end of the day, it’s not like there is magic here. There are only three things: compute, I/O, and the storage part,” he continues. “As long as you architect your system with a impedance match of these three things, so you are not I/O bound, you’re not compute bound and you’re not storage bound, then life is good.”
DataPelago already has paying customers using its software, some of which are in the pilot phase and some of which are headed into production, Goyal says. The company is planning to formally launch its software into full availability in the first quarter of 2025.
In the meantime, the Mountain View company came out of stealth today with an announcement that it has $47 million in funding from Eclipse, Taiwania Capital, Qualcomm Ventures, Alter Venture Partners, Nautilus Venture Partners, and Silicon Valley Bank, a division of First Citizens Bank.
















































